An overview of Slack’s architecture.
Introduction 🔗
In 2020, my friends and I started a Discord channel to host system design conversations, and we stopped after a while. We’ve decided to restart this two years later, using lessons from our first run. For now, we think the conversations will [mostly] hold on Twitter via @sysdsgn with live links so that people can watch live diagrams. However, we plan to be flexible with the format - we’ll keep the Twitter account updated with the latest information.
The first conversation for 2022 is about Slack’s architecture, inspired by this thread. In preparation for this discussion, I did a lot of research to understand Slack’s architecture, how it has evolved and why it has developed in that way. We didn’t cover everything I had hoped, but I think we left a bit more aware about how a service like Slack works and scales.
I’m writing this post for people who won’t find the space recording in the future because it expired and people who prefer text. I hope you find this useful.
This discussion did not aim to be a perfect decomposition of Slack’s actual architecture. Many things were approximations and assumptions, and some ideas could’ve been misunderstood entirely.
Slack 1.0 🔗
Let’s start with some initial requirements.
Functional Requirements
- We should be able to send messages within a channel
- Messages should be chronological and persisted
Non-functional Requirements
- Low Latency (should feel “real-time”)
- High Reliability
- We expect 4M users to connect per day & 2.5M users to connect simultaneously at peak
- We expect these 4M people to stay connected for at least 10 hrs/day
Initial Design 🔗
Here’s our high-level design for Slack
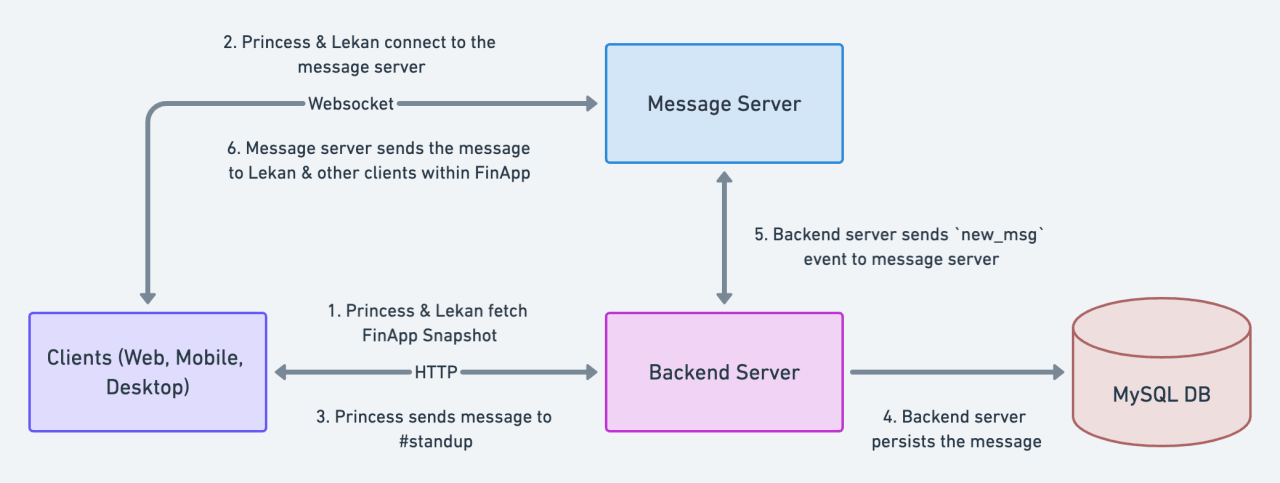
Components 🔗
- Clients: Web, Mobile, Desktop
- Message Server: Listens to updates from the backend server. Fans out real-time events to all clients (within a workspace).
- Backend: Server that contains the core logic of Slack. Knows what a user, workspace, channel are and how they interact. Knows about the message server and the DB and how to talk to them
- MySQL DB: Storage layer for everything that happens within Slack.
How does it work 🔗
To understand how this architecture works, let’s model a scenario where two users, Lekan and Princess, send messages to themselves within FinApp, their workspace.
Princess opens her client, which calls the backend to fetch the latest snapshot of FinApp. This snapshot is stored locally on her computer’s RAM. Lekan does the same.
The snapshot contains information about all the channels, groups, users, messages and so on within the workspace.
Asides from the snapshot, the backend server also returns the URL for the message server. Lekan and Princess' clients connect to the message server.
Lekan & Princess' clients will receive updates on any events within the FinApp via this WebSocket connection for the rest of their connections. Over one hundred types of events come across the WebSocket connection, including
new_msg,typing_indicator,file_upload,thread_replies, 'user_presence_change,user_profile_changeand so on. Clients receive these events and use them to update their local snapshots.The event names are names I came up with based on what I assume should be updated on Slack
Princess types and sends a message mentioning Lekan on #standup, a channel within FinApp. When she clicks enter, her client makes a POST
/messagerequest to the backend serverThe backend server persists the messages in the MySQL database and an acknowledgement to Princess' client, after which the message is seen as “delivered” by Princess. If anything fails here, Princess will see the option to “retry” on her client.
The backend server sends a
new_msgevent containing Princess’s message to the Message Server.The message server receives the
new_msgevent, processes it, and fans out the message to all the users in FinApp. After sending the message to Lekan’s client, he can read the message.
Assumptions + Small Maths 🔗
Now that we have a high-level design that meets our functional requirements, we need to confirm it meets our non-functional requirements. To do that, let’s make some assumptions and calculations:
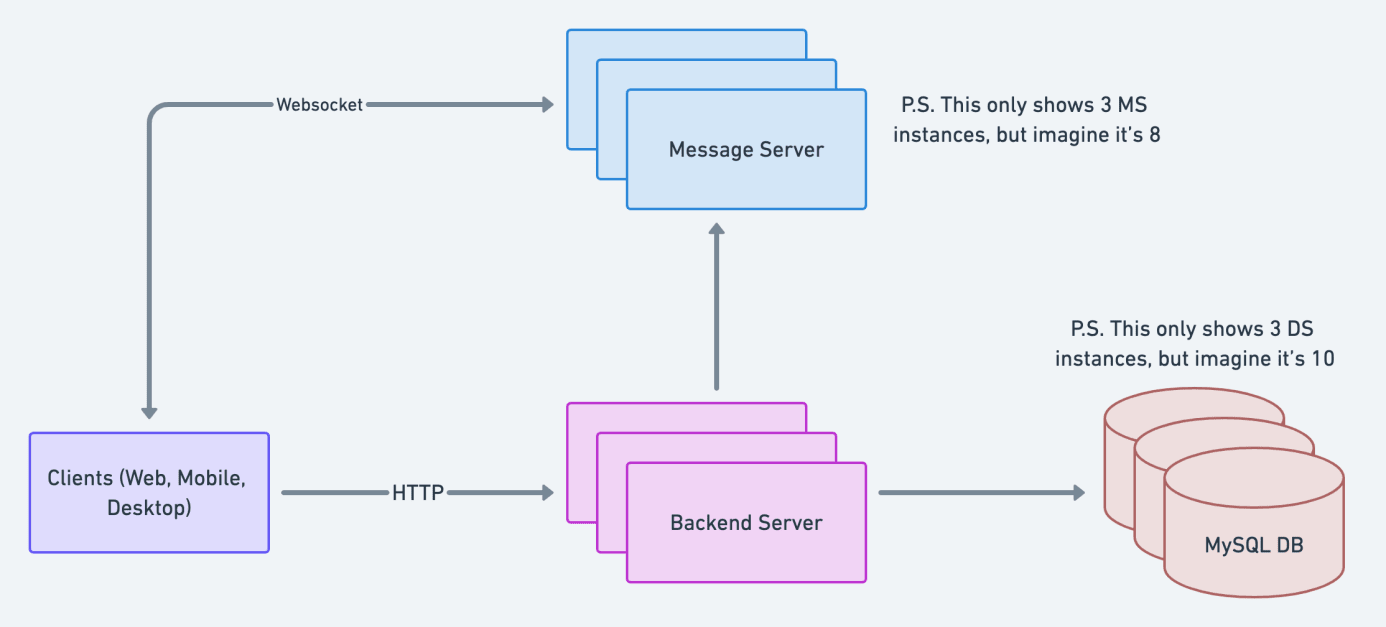
A message server can accept a max of 500K connections per day (and 500K simultaneous connections at a time). Since we expect 4M connections, we need 8 message servers (4M users / 500K connections).
Each person sends 50 messages a day, so the backend server, message server and MySQL server will receive 200 million (4 million users x 50 messages) message requests per day.
The average size of a workspace is 8k. This figure means that when one message is sent within a workspace, we expect the message server to send it at least 8000 times (one for each client).
So, we know the message server will receive at least 200 million
new_msgevents based on our previous assumption. This means the message server will need to send 1.6T (200M events x 8K clients) updates to clients via the WebSocket in a day. Wild. Suppose we assume that one message server can handle 250B events a day. In that case, we are still safe within our 8 message servers calculation from before (250B events x 8 message servers = 2T events). Nice.Before we go, how do should we shard the message server? We know that when the message server receives an update, it needs to fan it out - send it - to all relevant clients. It is much easier to do this if one message server serves all the clients in a workspace. If multiple message servers serve clients in one workspace, then multiple message server instances would need to communicate (think Interprocess Communication or IPC) for a fan out to succeed. We want to avoid that right now, so we shard the message server by workspace, meaning only one message server will handle all clients within a workspace.
Note: This doesn’t mean there’s a 1:1 mapping between MS and workspaces. One message server can handle a range of workspaces.
Finally, let’s talk about our MySQL server. Let’s assume that one MySQL server can successfully handle 20M/day; we will need 10 instances since we expect to receive 200M requests.
How do we shard our database? We can also shard our MySQL server by workspace, which works well for a few reasons:
- Sharding the database by workspace simplifies our queries. Different tables may reside in multiple instances if
the database isn’t sharded by workspace, complicating workspace queries that need to combine information from
various tables. For example, fetching data about channels might require combining
Channels,UsersandChannelMembershipstables. - Getting all the data needed from one instance also reduces our latency.
- Security Isolation works well with this model. If one database instance gets compromised, only workspaces on that instance will be affected.
- Sharding the database by workspace simplifies our queries. Different tables may reside in multiple instances if
the database isn’t sharded by workspace, complicating workspace queries that need to combine information from
various tables. For example, fetching data about channels might require combining
So, at this point, we safely meet our initial functional and non-functional requirements, and our architecture looks like:
Slack 2.0 🔗
We begin to plan a happily ever after with our updated architecture, but…Slack begins to grow. This shows up in two dimensions:
- The number of people connecting per day is now 8M (up from 4M), with 7M concurrent connections at peak time (up from 2.5M)
- The largest number of people in a workspace is now200K (up from 8K)
And with growth, we face some new issues. So, here we go again.
Issues 🔗
Many of these issues are interwoven in different ways, so don’t think about them as distinct and isolated problems; they affect one another, as in yin and yang.
Growing Workspace Snapshot Size & Large Client Memory Footprint
As a workspace grows, the size of its snapshot grows too. Many things influence the size of a snapshot, including the number of users, number of channels, total size of messages (audio + video + files), etc. To simplify this for us, we will assume that the size of a snapshot increases linearly with the number of users. Furthermore, we will assume that 1 user = 5 KB.
So, 500 users = 2,500,000 B (or ~2,500 KB or ~2.5 MB), 30,000 users = ~150 MB and 200K users = ~1 GB. These calculations mean that if a user in a workspace with 200k users needs to load a snapshot, they need to fetch and store 1 GB worth of data locally first. That’s 25% of a 4 GB RAM. Wild.
1024 B = 1 KB. 1024 KB = 1 MB. 1024 MB = 1 GB. 1024 GB = 1 TB.
Expensive Connection
Every time a user closes and opens Slack, they need to go through the client -> backend -> database path to update their local snapshot. With our current scale, we can expect at least 8M of these connections to go through that path every day. And if each user closes their laptop at least once (plausible), we will have 16M of these connections every day.
Apart from the I/O operation count, let’s talk about latency. If we assume that a snapshot only contains
channelsandusers, the time complexity of the algorithm fetching the snapshot would be O(channels x users). According to this podcast [at 12:41], " all else being equal, the number of channels is roughly proportional to the number of users". While this statement was made in 2016 and may not be accurate in 2022, it’ll have to do. So, if channels == users, our complexity becomes O(n^2), where n = users.Every time a user tries to fetch a snapshot from the database, we have this quadratic call. Think about this in the context of the previous issue too.
Thundering Herd
Finally (as in our final consideration for this essay, not the final problem Slack faced in this part of their timeline), there’s the possibility of thundering herd!
What is thundering herd (a.k.a mass reconnects)? It refers to a point (or period) when multiple clients try to connect to the backend simultaneously. A simple example of when this can happen in Nigeria is when the power goes out temporarily in a company that uses Slack. Because the power is out, everyone gets disconnected from the internet, and once the light is back, everyone’s Slack client will try to connect to the backend simultaneously.
Think about this in the context of the previous issue(s) and the fact that the network has a max bandwidth. Quick thought here: if the theoretical Nigerian company has 30,000 users, we can say from our previous calculations that this means each user has to fetch a 150MB snapshot across the network. If 30,000 of them are trying to fetch this snapshot simultaneously, then we’re attempting to drag 30000 x 150MB = 4,500 GB’s (or~ 4.5TB’s) worth of data across a network within a short period. Can the network handle that?
It’s useful to mention that another type of thundering herd is DDos.
Improvement 1: Fat + Lazy Client 🔗
Clients need to fetch the full snapshot and store it locally at boot (or reconnect) in the old architecture. This improvement makes a small change to that: clients will load partial data at boot (or reconnect) and request the rest on demand (lazy loading).
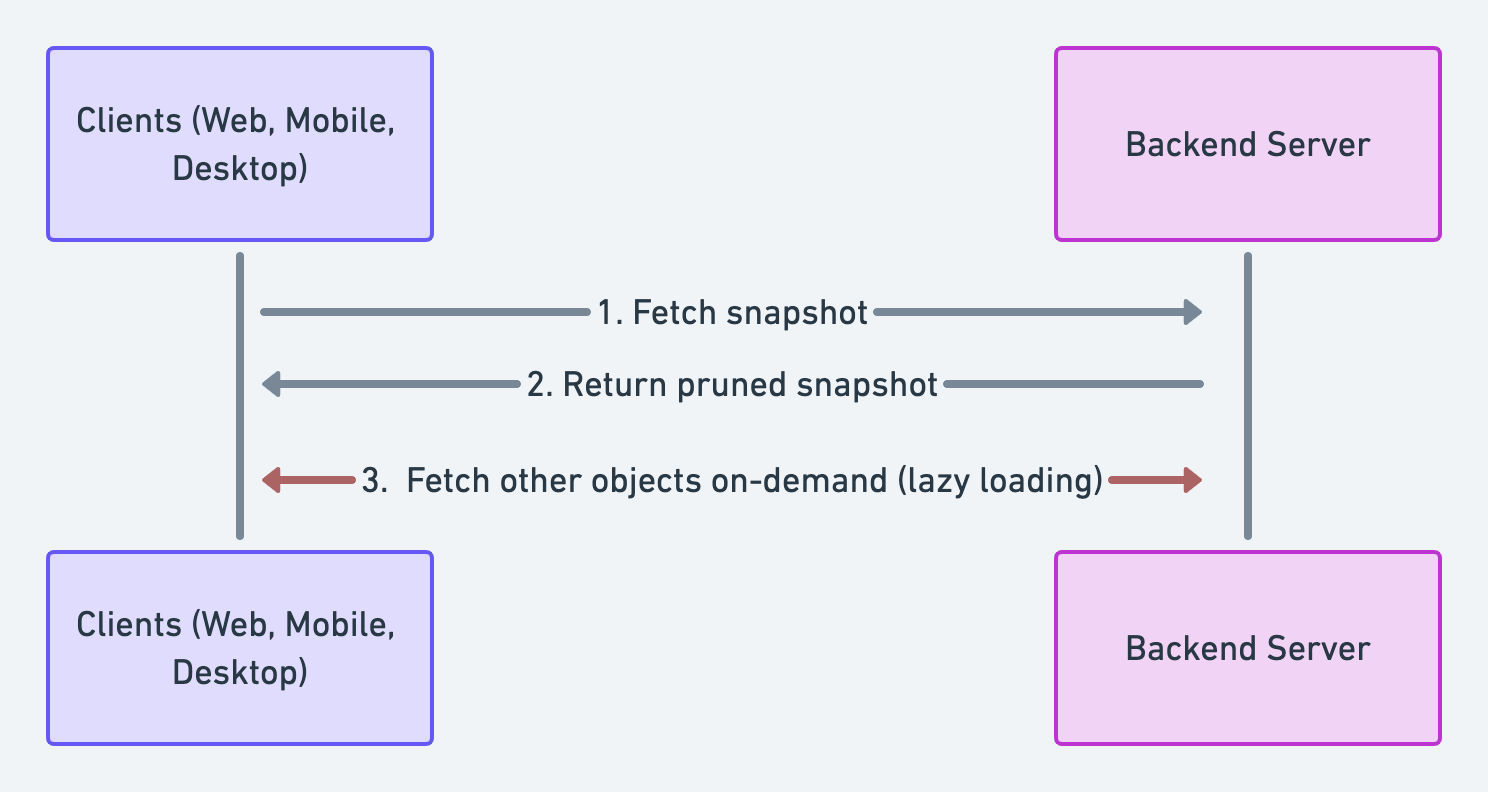
Making this work requires changing the client code because clients can no longer assume that all data is accessible locally; they will need to fetch some data on demand from the backend.
Which of the issues mentioned above does this improve?
Limitations
- Still susceptible to thundering herd (e.g. if clients dump their cache or wireless connectivity issues)
- Client memory footprint still grows with team size
- Every time an object is fetched lazily, we need to make the round trip to our backend (hello, expensive connection?)
Can we improve on this?
Improvement 2: Flannel 🔗
Flannel is an edge cache service. It is a read-only query engine that is backed by a cache. Let’s break this down:
- Flannel is a query engine. It can respond to query requests and serve responses from its cache. We’ll come back to this in the next section.
- Flannel is backed by a cache. For our purposes, Flannel IS a cache. You can store things in the RAM via Flannel.
We’ll focus on the Flannel’s cache role first; let’s look at how it changes our [old architecture]
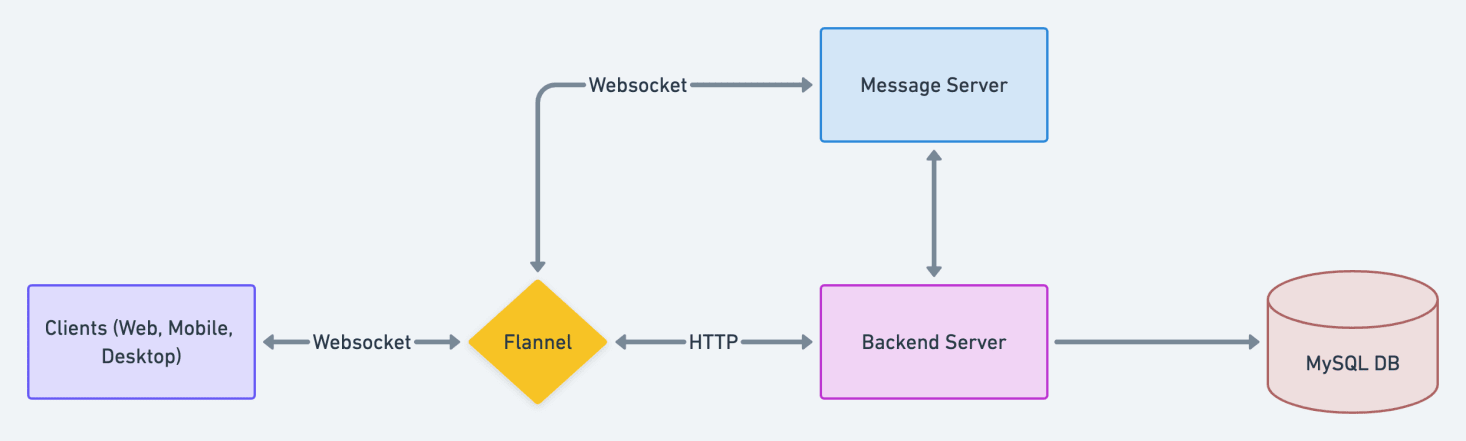
Note: write operations don’t happen through Flannel. Meaning Flannel’s cache policy is write-around. Read about some other policies here.
So, Flannel sits in two paths. First, Flannel sits in the HTTP path between the clients and the backend server. Its position means that any calls to the backend pass through Flannel, allowing us to cache the results of expensive requests. One of such requests is the workplace snapshot. Once at least one client has retrieved the workplace snapshot, every other client can fetch the snapshot from Flannel. Applying what we know to this [scenario](#How does it work) we detailed earlier, we know that Lekan’s client will not need to make a round trip to the backend server to fetch Flannel because Princess' client has done it once.
Note: When the last client disconnects, Flannel deletes the workspace data from the cache. It helps to manage space.
Secondly, Flannels sits in the Websocket path between the client and message server. You will recall that the WebSocket path is how clients receive updates to update their local snapshot. Flannel sitting in that path means that Flannel can also update its copy of the workplace snapshot before passing it to clients. So, whenever a new client tries to fetch the snapshot, it will always receive an updated copy from Flannel.
With this improved architecture, we need less expensive connections to the MySQL server because responses are cached in Flannel, which is deployed at edge locations. Furthermore, Flannel offers lower latency for subsequent fetches of a workplace snapshot because it stores data in memory - sequentially accessing data in memory is at least 80x faster than doing the same on a disk. Finally, according to this talk, Flannel can handle 1M+ client queries/sec (and up to 5M+ simultaneous connections at peak), which means that Flannel helps with our thundering herd problem and furthers our the achievement of our initial “real-time” requirement. Sweet.
Improvement 3: Flannel Reloaded 🔗
Okay, so we understand Flannel’s primary role as a cache. Let’s dive into a few more details.
Distributed Flannel
For our scale, we know that we need multiple instances of Flannel to be deployed. Whenever we deploy multiple instances of a service, the next logical question is: how do we route requests effectively to these instances? We want to minimize hotspots, minimize latency and maximize I/O operations.
Flannel is deployed across multiple regions, and in each region, there are multiple Flannel instances. Slack uses GeoDNS to route incoming requests to the appropriate edge region based on the client’s geographical location. Once a request is routed to a region, Slack uses HAProxy (in that region) to find the Flannel instance with the snapshot for that particular request and user.
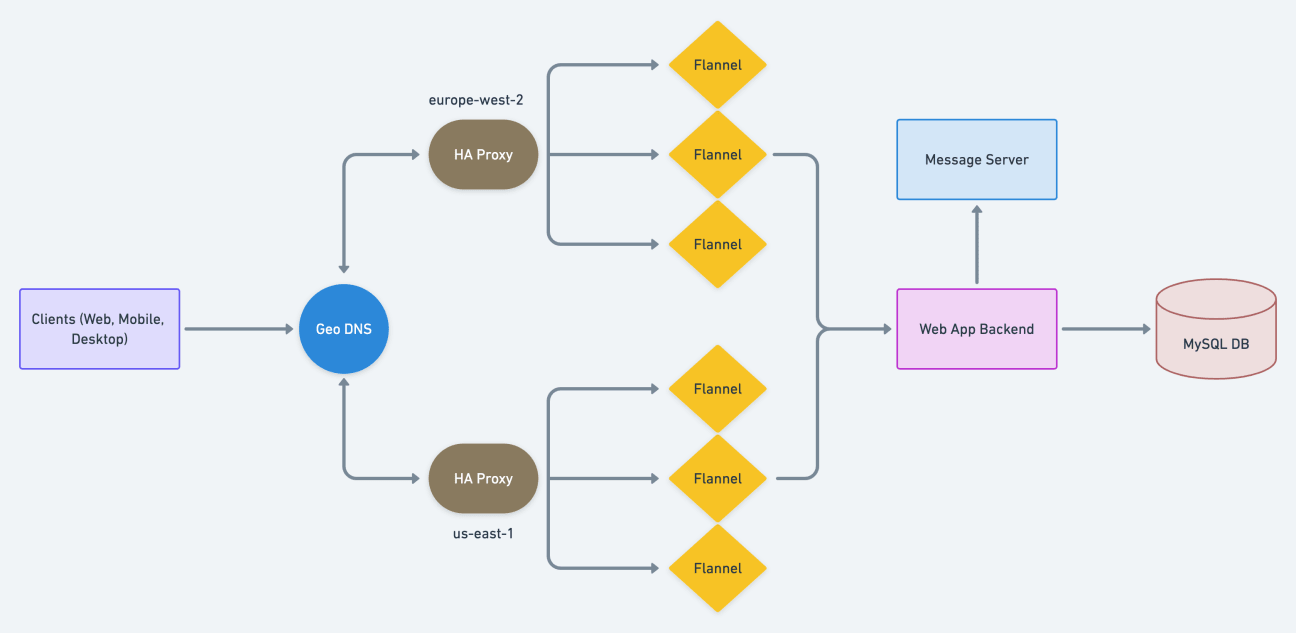
No Flannel instance in a region will have the snapshot for a request and user if that user is the first in their workspace to connect that region. In that case, one of the Flannel instances in the region will fetch the snapshot from the backend server, store it in its cache and use it to respond to the request. This Flannel instance in that region that stores the snapshot is the instance that will respond to any future requests in that region from users in that workspace - in this way, we say Flannel has workspace affinity.
Query Engine
We mentioned earlier that Flannel is a query engine because Slack moved some query operations to Flannel (from the backend server). It can effectively serve these requests because it sits on the edge and contains an updated snapshot of workspaces.
Some features powered by Flannel include:
Quick Switcher: find users and quickly via a quick switch command (
Cmd+Kfor Macs,Ctrl+Kfor Windows).Mention Suggestions: look-ahead suggestions when you try to mention users in a channel Seeing names in a channel during a @mention. {desc} x {image}
Preemptive Updates
This is one feature I found cool about Flannel. I’ll walk through a scenario to explain - the key thing to remember is that clients now load partial snapshots at boot and request other objects on-demand in our current architecture.
To explain the feature, I’ll use a scenario between our two users from before: Princess and Lekan, who belong to the same workspace, FinApp.

Princess loads up Slack, and the only channel she has lazily loaded is #standup
Lekan loads up Slack, and the only channel he has lazily loaded is #music
Princess mentions Lekan in #standup, and the client sends the request to the backend server
The backend server persists this message in MySQL and sends this message to the message server
The message server receives this message and fans out to Lekan’s client because Lekan is in the FinApp workspace
[!IMPORTANT] This fan out passes through Flannel (because it sits in the path), and Flannel realizes that Lekan’s client has not yet loaded #standup, so Flannel pre-emptively enriches the payload containing the message update with the data for #standup too.
This is important because what would have happened otherwise is that Lekan’s client will receive a new message from Princess in #standup and realize it hasn’t loaded the channel yet. It will then request for #standup’s data from Flannel and wait for it to return before it renders the message from Princess. This pre-emptive mechanism from Flannel prevents an extra call.
Whew, we’ll stop here. I hope that was fun.
Answered Questions From The Space 🔗
Are there load balancers on any level? Yes, the HAProxy (see image under Distributed Flannel above).
Why not use Memcache or Redis as the cache. Why is Flannel a thing? Flannel also doubles as a query engine with more sophisticated querying and filtering capabilities than Redis or Memcache can offer.
How does Flannel update its data locally? Flannel sits in the Websocket path between the client and the message server. Flannel uses the updates that come across the path to update its data locally.
Is Flannel read-only? Yes.
Do workspace and database shards have a 1:1 mapping? No, a database server shard handles a range of workspaces, not just one.
What is HAProxy? Read Distributed Flannel.
How are Flannel instances deployed? I don’t know for sure, but let’s speculate. One thing you need to think about is how much management you want to do. You can run on EC2 directly. You can run in containers (and manage with Kubernetes). Docker containers and Kubernetes have self-healing mechanisms, which means that if there’s a crash, a new instance is deployed as a replacement. The reason why an instance crashes is important. An endless self-healing loop could be problematic if it’ll just keep crashing. Maybe we can set max restarts, or we could use monitoring + alerting to tell us when something doesn’t look right.
Does Slack implement rate-limiting? Slack implements something called “Automated Admission Control” for servers. This mechanism rejects any request once a server has reached its limit. “Limit” is measured through factors like memory, the number of concurrent requests, network throughput and so on. It’s also possible that Slack rate limits the number of requests certain users can make to specific endpoints.
Flannel is deployed to edge locations. Are there multiple instances of Flannel deployed in one region? If yes, does Flannel have a data storage layer? Yes, to the first question. Read Distributed Flannel. No, it doesn’t, AFAIK. Introducing a storage layer includes all types of complexity, e.g. the need for interprocess communication.
How does Flannel recover when it crashes? I’m speculating here, but another instance within the region will begin to handle all the workspaces for the crashed instance. We can split the workspaces handled by the crashed instance properly to all the remaining healthy Flannel instances through consistent hashing. Doing this can prevent cascading crashes.
Final Thoughts 🔗
As you go, I leave you with some questions to ponder:
- Flannel sits on the WebSocket path to receive real-time event updates. However, in the current architecture, Flannel receives a lot of duplicated events from the message server. How can we fix this?
- Slack migrated from JSON event streams to Thrift event streams. Why do you think that is?
- Say Flannel experienced cascading failures because of a bug. What are future improvements you can make to the architecture to prevent such a scenario from “cascading” in the future?
- We spoke briefly about the MySQL server being sharded by workspace. Say this mechanism created too many hotspots; how do we adjust it?
See you next time!